About XtalPi
XtalPi is an innovative technology company powered by artificial intelligence (AI) and robotics. Founded in 2015 on the MIT campus, XtalPi is dedicated to driving intelligent and digital transformation in the life science and new materials industries. With tightly interwoven quantum physics, AI, cloud computing, and large-scale clusters of robotic workstations, XtalPi offers a range of technology solutions, services, and products to accelerate and empower innovation for biopharmaceutical and new materials companies worldwide.
Ilum is an in-house C++ application developed by XtalPi that specializes in crystal structure comparisons and has been extensively integrated into XtalPi's internal crystal structure prediction (CSP) process, a step that lays the foundation for drug formulation and manufacturing that ensures the safety and IP protection of new medicines. This application helps in comparing multiple polymorphs of candidate drugs and identifying the superior polymorphs best fit for drug-making, thereby enhancing research efficiency and drug developability, shaving months off the drug development cycle.
“Crystal structure prediction (CSP) is becoming a standard procedure in drug R&D. Our partners place great trust in its accuracy and reliability, as it offers valuable insights that accelerate key steps of drug development, while also bolstering the safety and intellectual property (IP) protection of new medicines. Crystal structure comparison, an essential application within the computationally intensive CSP, necessitates a significant amount of computational power. This poses a significant challenge as we continually refine and optimize our CSP process. By utilizing Intel® toolkits (Intel® oneAPI DPC+/C+ Compiler, Intel® oneAPI Math Kernel Library [Intel® oneMKL], Intel® Integrated Performance Primitives [Intel® IPP], and Intel® VTune™ Profiler) and employing techniques such as instruction set optimization and function substitution, we have significantly improved the performance of crystal structure comparison tool. This enhancement accelerates the drug R&D process for our customers, providing faster execution and numerous benefits. Additionally, it allows us to better exploit the hardware’s potential, resulting in increased return on investment for the R&D project.
Enhancing the Performance of Ilum
The efficiency of Ilum directly influences the time and core cost of crystal structure prediction and is critical for the economics and efficiency of drug research and development (R&D). Therefore, optimizing the performance of Ilum is of great significance. The computational cost of Ilum primarily depends on the number of equivalent traversal paths in the molecular graph, and highly symmetric molecular structures pose greater challenges. Optimizing the Ilum algorithm will help address this challenge.
XtalPi collaborated with Intel to explore the use of the Intel® oneAPI toolkits. The application adopted the Intel® oneAPI DPC++/C++ Compiler with different optimization level flag as well as instruction set optimization. Meanwhile, they also used the Intel® VTune™ Profiler, a visual performance analysis tool, to identify hotspots and optimized the implementation by replacing local functions with those in the Intel® oneAPI Math Kernel Library (Intel® oneMKL) and Intel® Integrated Performance Primitives (Intel® IPP).
Optimizations
The computational expense of Ilum hinges on the count of traversal paths within the molecular graph. By this principle, four test cases have been carefully chosen, particularly noting that crystal structures with high symmetry pose greater challenges: LC (low difficulty case), MC (medium difficulty case), HC (high difficulty case), and EC (extremely high difficulty case). Each case includes an ample number of structures to ensure that the basic version of Ilum runs for over 10 minutes, allowing for precise profiling.
Optimization with Intel® oneAPI DPC++/C++ Compiler
The Intel® oneAPI Base Toolkit (Base Kit) is a core set of tools and libraries for developing high-performance, data-centric applications across diverse architectures. The Intel® oneAPI DPC+/C+ Compiler can compile ISO C++ and SYCL; avoid proprietary lock-in with a cross-industry, open, standards-based unified programming model; realize all the hardware value; and deliver great performance from industry-leading Intel® compiler technology.
GCC* is the original compiler for the application Ilum. To compare the optimized performance, XtalPi selected GCC-12.1 (with O3 optimization) as the baseline for this case study. After changing the compiler from GCC to Intel® oneAPI DPC+/C+ Compiler, XtalPi tested various optimization levels and ultimately selected based on its speed and accuracy. XtalPi then evaluated the performance of Intel® Advanced Vector Extensions 2 (Intel® AVX2) and Intel® Advanced Vector Extentsions 512 (Intel® AVX-512), as well as the impact of applying fast-math. ZMM was manually turned on by adding the "-mprefer-vector-width=512" flag. The test result showed that the binary, Intel® AVX-512 with fast-math and O3 optimization, emerged as the top performer, and it was chosen for further optimization.
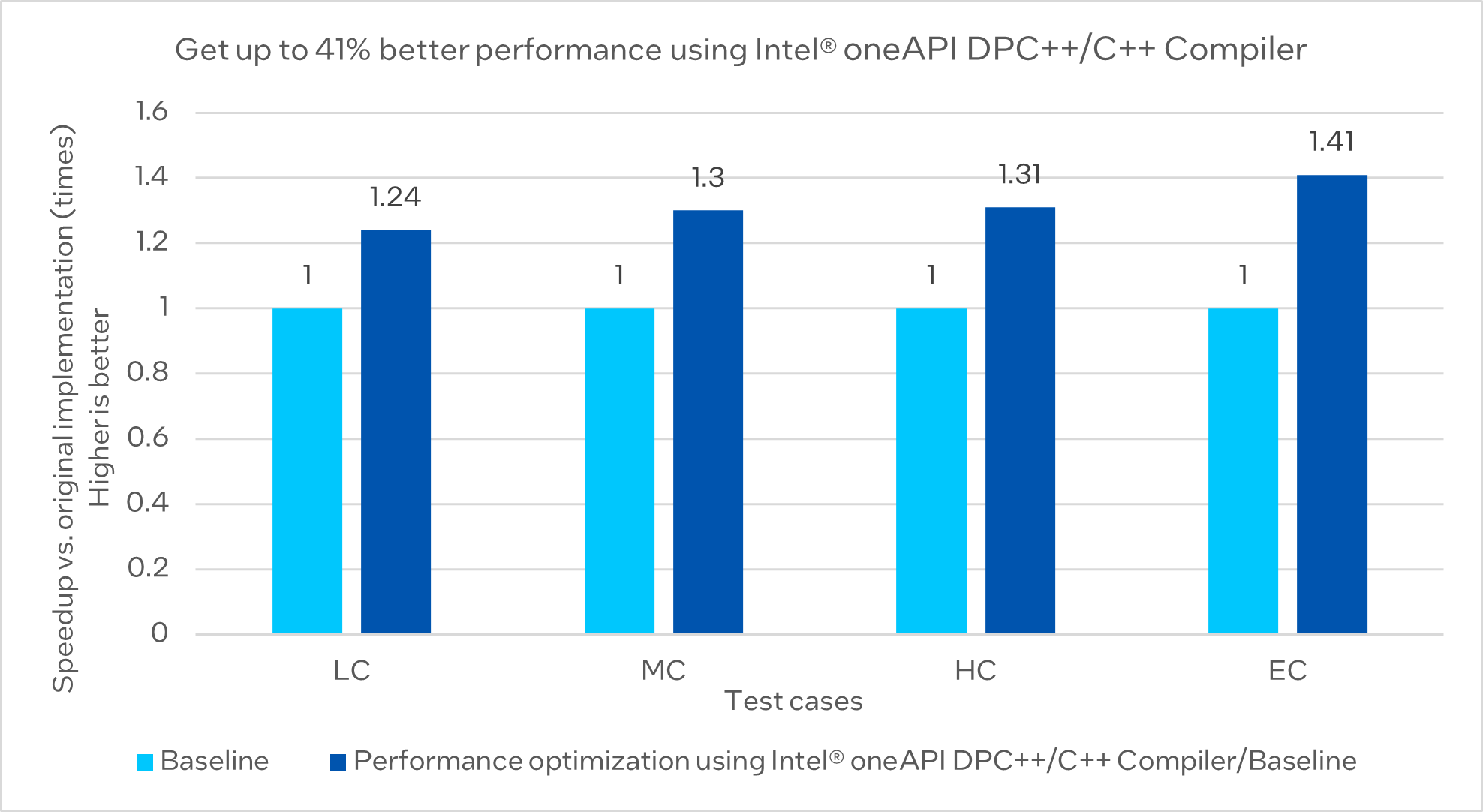
Figure 1. Performance comparison between baseline and performance optimization using Intel® oneAPI DPC++/C++ Complier
Performance Optimization Using Intel® oneMKL
XtalPi used the Intel® VTune™ Profiler to find hotspot functions within the code and identify the key hotspot for further optimization. Hotspots analysis and Microarchitecture Analysis helped in understanding the application flow and identifying sections of code that consumed a significant amount of execution time. This served as a starting point for the following algorithm optimization.
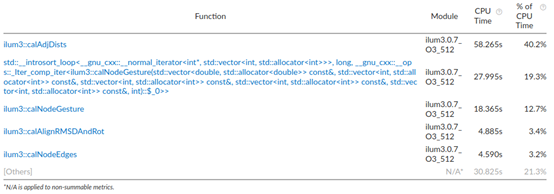
Figure 2. Analysis result of Intel® VTune™ Profiler
As shown in Figure 2, Intel® VTune™ Profiler identified that the "calAdjDists" function accounted for nearly half the cost. With this information, XtalPi optimized the Euclidean distance calculations by replacing the original for-loop implementation with the cblas_dgemm function from Intel® oneMKL. Intel® oneMKL, containing the Optimized Library for Scientific Computing, is the fastest and most-used math library for Intel®-based systems. Its core functions include BLAS, LAPACK, sparse solvers, fast Fourier transforms (FFT), random number generator functions (RNG), summary statistics, data fitting, and vector math.
This modification significantly increased the execution speed in the four difficulty cases.
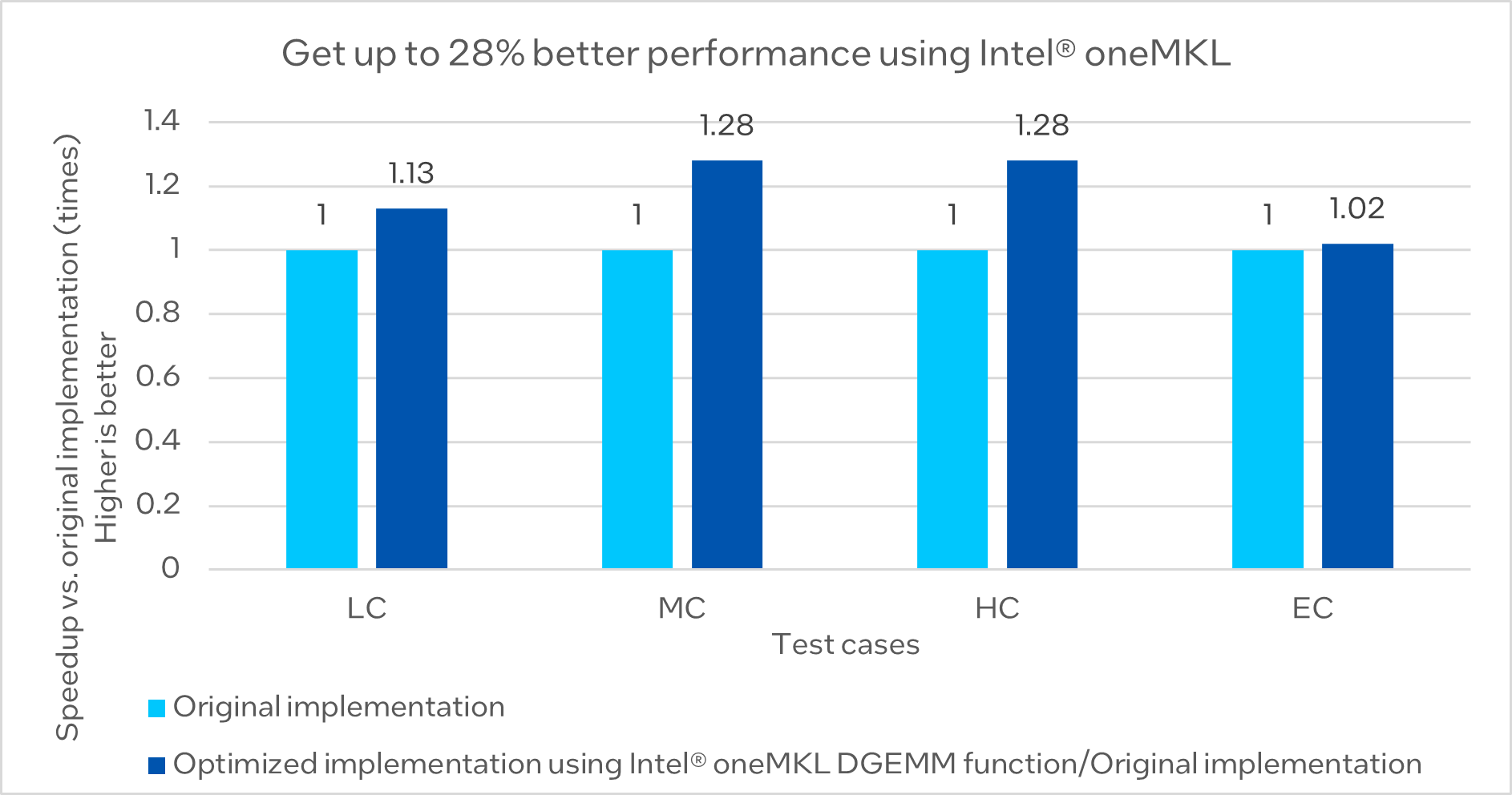
Figure 3. Performance comparison of the original implementation of Euclidean distance calculation and optimized implementation using Intel® oneMKL DGEMM function
Performance Optimization Using Intel® IPP
Another optimization potential in the application is the "sorting" function, which can be optimized using Intel® IPP. Intel® IPP is an extensive library of ready-to-use, domain-specific functions that are highly optimized for diverse Intel architectures. Taking advantage of Single Instruction, Multiple Data (SIMD) instructions, it can help developers improve the performance of computation-intensive applications, including signal processing, data compression, video processing, and cryptography, and reduce the cost and time to market for software development and maintenance.

Figure 4. High Optimization Potential for Intel® IPP
The "std::sort" function is a standard function provided by the Standard Library and has shown good performance. Further analysis of the microarchitecture using the Intel® VTune™ Profiler reveals that it still has a high execution time, a high CPI rate, and significant branch misprediction issues, indicating that there is room for optimization in its implementation. Intel® IPP offers alternative interfaces such as ippsTopK_32f and ippsSortRadixIndexAscend_64f, which can be used to replace the original sort function. Such an approach resulted in a noticeable enhancement in the overall efficiency of all cases, as shown in Figure 5.
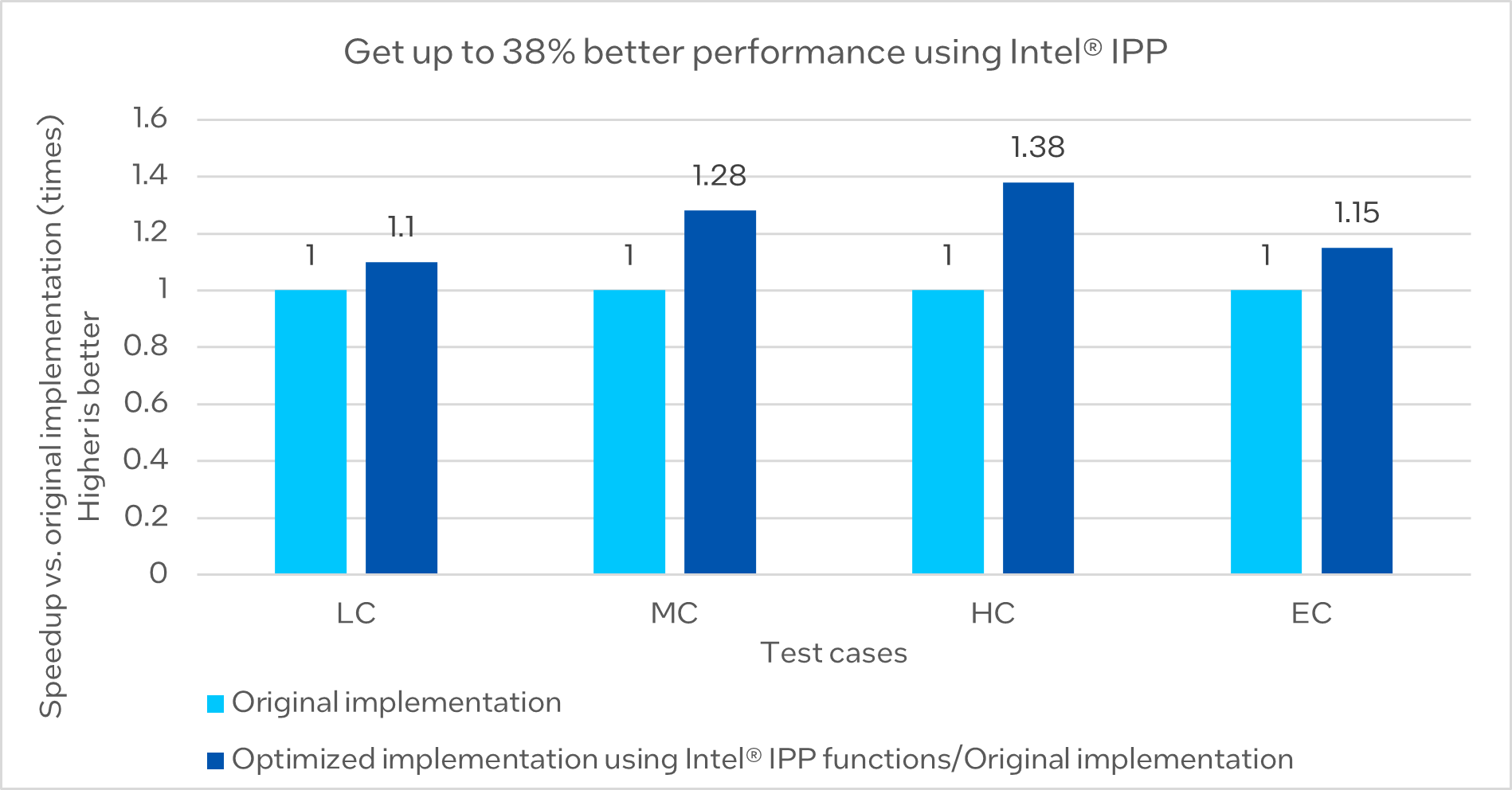
Figure 5. Performance comparison of original implementation of sort function and optimized implementation using Intel® IPP
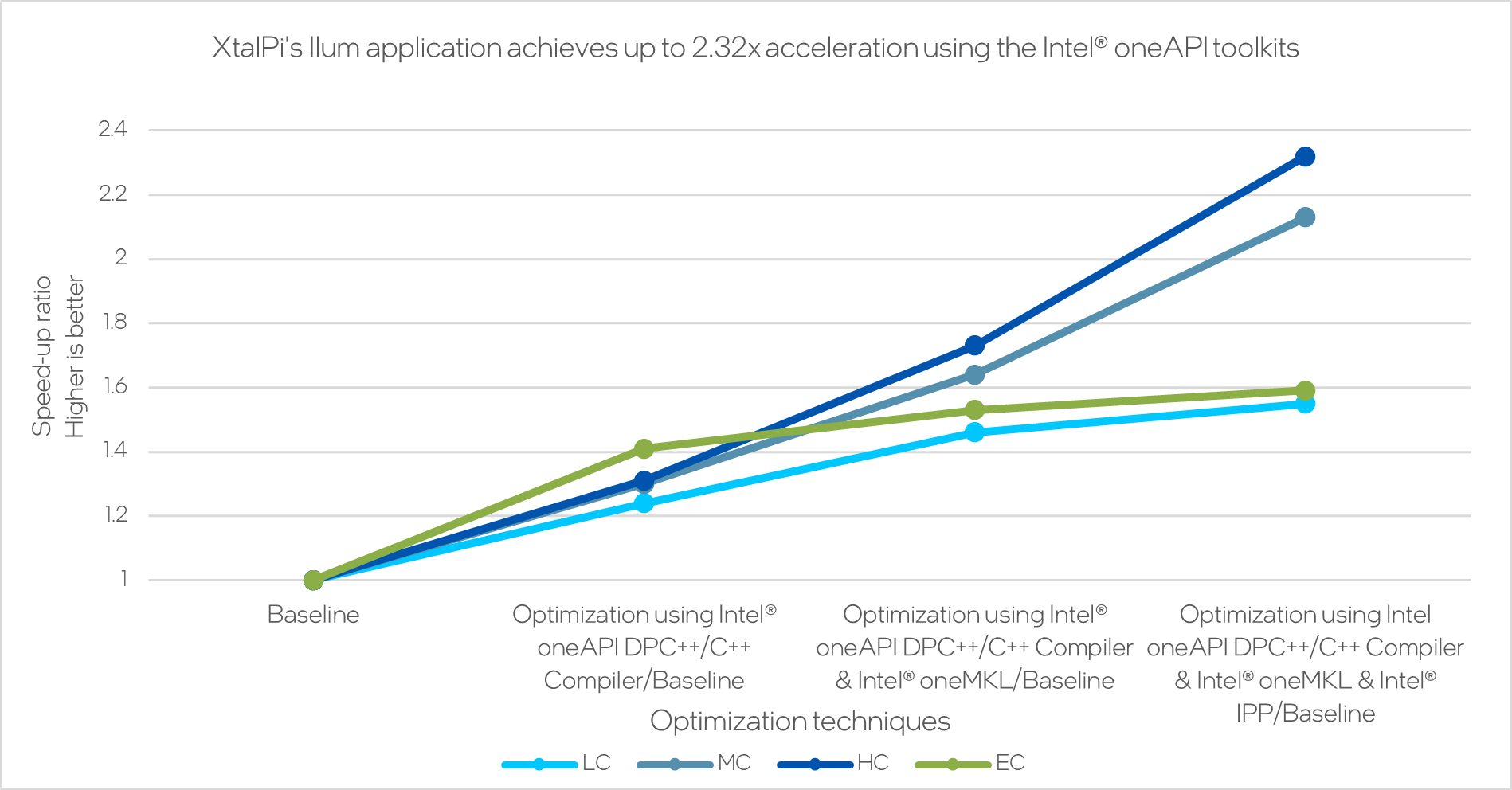
XtalPi has achieved significant performance improvements for the Ilum application through multiple rounds of optimization using the Intel® toolkits. These optimizations have had a positive impact across different difficulty levels, resulting in an impressive performance improvement of up to 2.32x.
Testing date: Performance results are based on testing by XtalPi as of October 2023 and may not reflect all publicly available security updates. Configuration details and workload setup: Intel® Xeon® Platinum 8480+ processor @ 2.00 GHz, 256 GB DDR5 memory, DC P4510 1TB NVMe U.2 SSD from Intel, Intel® oneAPI DPC+/C+ Compiler version: 2023.2.0.20230622, Intel® oneMKL version: 2023.2.0, Intel® IPP version: 2021.9.0, Intel® VTune™ Profiler version: 2023.2.0 (build 626047), 20.04.1-Ubuntu* 5.15.0-76-generic; Baseline compiled using GCC version 12.1 with -O3 optimization; LC = Low Difficulty, MC = Medium Difficulty, HC = High Difficulty, EC = Extremely High Difficulty. Intel technologies may require enabled hardware, software, or service activation. Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Figure 6. Performance improvements using different optimization techniques.
Conclusion
The optimization process and its outcomes serve as strong evidence of the substantial performance improvements brought about by the Intel® toolkit for Ilum. These enhancements have led to an impressive 2.32x increase in the speed of the online version of the Ilum application. This exciting outcome has inspired XtalPi to delve deeper into the vast optimization opportunities available within their in-house toolkit.